
AI正走到一個重要分水嶺。
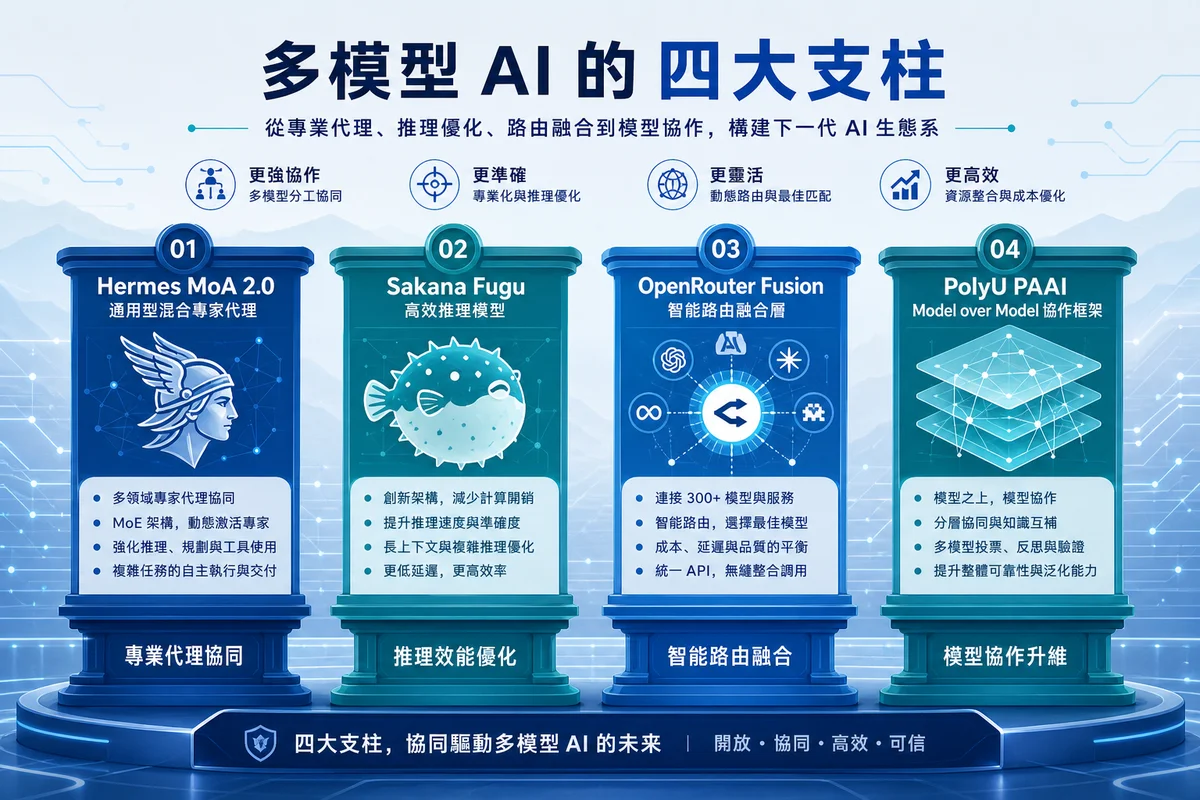
過去,業界普遍相信只要把模型做得更大、數據餵得更多、算力堆得更高,人工智能便會自然走向AGI(Artificial General Intelligence,人工通用智能)。可是,近期Hermes MoA 2.0、Sakana Fugu、OpenRouter Fusion等聚合模型與多智能體系統的發展,提出了另一條路線:下一階段AI能力提升,未必只來自單一模型,而更可能來自多模型協作、能力融合、專家能力聚合,以及「平時低成本、必要時高智能」的分層推理架構。
從這個角度看,香港理工大學人工智能高等研究院(PAAI)和楊紅霞教授團隊較早前提出的Model over Model(MoM),並非天馬行空,而是與全球AI前沿趨勢高度一致。近期業界不同研究與產品方向,都在不同層面證明同一件事:AI正由「堆算力」走向「建團隊」;由單一模型競賽,走向多模型協作、融合與演化。
PAAI的方向,正是把這種聚合思維由應用層的推理協作,推進至更底層的預訓練、持續預訓練、模型融合與知識蒸餾。對香港而言,這尤其重要。香港缺乏大規模訓練算力,又受到地緣政治和供應鏈限制,訓練算力是最大缺口;但香港同時擁有大量專有知識、專業場景和高質量研究數據,這些知識往往束諸高閣,未能真正轉化為模型能力。
Hermes:用多模型協作處理複雜推理
Hermes Agent近期版本v0.18「Judgment Release」引入Mixture of Agents 2.0(MoA 2.0)。Hermes的核心概念,是讓用戶把不同供應商的大語言模型組合成自己的「模型混合體」,並在Hermes內像調用一般模型一樣使用。換言之,用戶不再被單一模型或單一供應商綁定,而是可以把OpenAI、Anthropic、Google、開源模型、本地部署模型等不同能力,按需要組合成多模型推理系統。
Hermes行政總裁Teknium指出,MoA 2.0可以把任何供應商的模型組合成自訂mixture,並以Hermes內的preset形式使用。他亦提到利用Opus與GPT等模型共同組成MoA,在HermesBench測試中超越單一頂級模型表現。這反映出一種新的工程邏輯:最強能力未必來自單一模型,而是來自多個模型之間的分工、互補與綜合判斷。
實際應用上,這種架構的意義在於,一般用戶並不需要每條問題都調用最昂貴的前沿模型。日常業務問題,例如數據整理、文件摘要、客戶服務、內部流程查詢、初步分析等,可以交由較低成本或本地部署模型處理。在一般使用情況下,企業甚至可利用DGX Spark運行SGLang,配合Qwen等開源模型,處理大量日常業務任務。
當系統遇到特別複雜的推理任務,例如策略判斷、跨文件分析、技術架構設計、法律或合規風險比較、假設推演等,才啟動/moa,讓多個LLM從不同角度分析問題,再由aggregator model綜合答案。這樣做的好處,是把高成本推理能力留給真正需要的場景。若多模型聚合的結果可接近甚至挑戰最前沿模型,而平日大部分任務仍由低成本模型完成,整體AI使用成本便可大幅下降。
Sakana Fugu:把多智能體包裝成一個模型
另一個重要發展,是Sakana AI推出Sakana Fugu。Sakana AI共同創辦人Llion Jones是2017年Google改變AI發展方向的論文《Attention Is All You Need》主要作者之一,也是Transformer架構的重要開創者之一。
Sakana一直因Evolutionary Model Merge和群體智能研究備受關注;其研究方向是AI能力可以透過不同模型的演化、融合和互補而提升,不一定只靠垂直放大單一模型。Sakana Fugu則把這種思路產品化。
Fugu標榜「Multi-Agent System as a Model」。表面上,用戶調用的是一個OpenAI-compatible API;但系統內部可以利用多個agent或模型協作,完成複雜推理與生成。Fugu分為一般版Fugu和Fugu Ultra,可按工作負載選擇不同能力與延遲平衡。一般Fugu強調較低延遲和穩定性能,適合日常工作、編程、代碼審查和聊天服務;Fugu Ultra則面向高難度任務。
這種設計把多智能體協作隱藏在一個API之後。對開發者而言,整合方式仍像使用一個普通模型;背後則由系統根據任務需要調度不同agent和模型。這與Hermes MoA的形態不同,但方向一致:AI不再只是「一個模型回答一切」,而是一個模型網絡或agent群體共同完成任務。
OpenRouter Fusion:多模型混合的另一種實踐
OpenRouter推出Fusion也是同一技術主線。Fusion可理解為「按需要啟動的多模型評議機制」。當基礎模型判斷某個問題值得投入更多時間和成本處理,Fusion便會把同一prompt並行交給多個模型,讓各模型從不同角度回答,再由judge model比較答案,整理出共識、矛盾、遺漏、獨特洞察和盲點。外層模型再根據結構化分析,生成更完整、更可靠的最終回應。
這與傳統router不同。一般模型router是「選一個模型」:簡單問題交給便宜模型,困難問題交給昂貴模型。Fusion則不只是選一個模型,而是在需要時讓多個模型同時參與,形成臨時「LLM委員會」。目的不是永久增加成本,而是在真正值得思考的問題上,以多角度分析換取更高質量答案。
OpenRouter亦強調,Fusion不一定應作為所有任務的預設模型。以編程為例,日常代碼修改可由基礎coding model直接完成;若問題涉及系統架構、最佳實踐、複雜debug或技術取捨,才值得調用Fusion,讓多個模型共同分析。「平時低成本、必要時高智能」的設計,與Hermes MoA 2.0和Sakana Fugu一脈相承。
業界正形成一種新的AI成本結構:不是每次都使用最貴模型,而是把AI系統設計成分層架構。第一層處理大量普通任務,追求低成本和低延遲;第二層在遇到困難任務時啟動多模型協作,追求高可靠性和高推理能力;第三層則進一步把經驗、知識和推理流程沉澱回模型、agent或企業知識系統之中。
聚合模型趨勢,側面證明PAAI方向正確
Hermes、Sakana Fugu和OpenRouter Fusion共同說明,AI正在從「堆算力」轉向「建團隊」。過去,AI能力提升依靠更多參數、更大數據集和更昂貴GPU叢集。現在,關鍵問題變成:如何把不同模型組合起來?如何讓便宜模型與昂貴模型分工?如何讓本地模型與雲端模型互補?如何在成本、延遲、私隱和推理能力之間取得平衡?
這個轉向對企業尤為重要。企業部署AI時,最關心的往往不是單次demo能否達到最高分,而是長期運行成本、數據私隱、延遲、可控性和可擴展性。日常任務可由開源模型或本地模型完成,複雜任務則使用多模型聚合,在成本與效益之間取得合理平衡。這也是為何DGX Spark、SGLang、Qwen等本地推理和開源模型生態,與MoA、Fusion、Fugu等多模型協作架構形成互補。
這個趨勢也為大學和研究機構重新參與AI基礎能力建設,提供了新的想像。未來AI不再只靠少數企業訓練超大模型,而可以靠不同領域模型、不同專家agent、不同研究機構的知識互相融合。大學因而有機會重新成為推動AGI發展的重要力量。
理大剛成立人工智能高等研究院(PAAI),嘗試以更開放、更務實的方法推動AGI。PAAI的發展正切中AI下一階段的核心。業界的MoA、Fugu和Fusion,主要證明「推理時聚合」有效;PAAI和楊紅霞教授團隊提出的MoM,則進一步追問:如果推理時的多模型協作已經能顯著提升能力,能否把這種協作提前到模型訓練、持續預訓練和知識融合階段?不同大學、不同學科、不同產業是否可以各自建立專精模型,再通過融合形成更強的樞紐模型?這正是MoM的價值。
Scaling Law的瓶頸
一直以來,生成式AI發展遵循所謂Scaling Law:參數越多、數據越多、算力越強,基礎模型性能越好。然而,基礎模型愈造愈大,也逐漸遇上瓶頸,必須另闢蹊徑。
首先是訓練成本與能耗過高。訓練萬億參數模型,需要極高硬件投資,能耗亦相當驚人。其次是高質量數據日漸稀缺:網上可用於訓練的高質量公開數據逐漸耗盡,敏感數據、專有數據和專業知識又難以直接共享。最後,單一基礎模型能否無限擴大,正受到愈來愈多質疑。
基礎模型訓練可分為兩個階段:首先是預訓練(Pre-training),其次是後訓練(Post-training),包括監督式微調(Supervised Fine-tuning)和強化學習(Reinforcement Learning)等。然而,模型的深層知識注入,實際上主要發生在預訓練階段。通過fine-tuning注入全新知識,效果往往遠不如預訓練。
另一個關鍵問題是,預訓練成本過高。若要推動AI真正進入科學研究和產業應用,就必須降低訓練門檻,讓更多大學、研究機構和不同學科團隊能夠參與其中,而不是只由少數大型科技公司掌握基礎模型創新。
楊紅霞教授團隊的Model over Model
PAAI推動「Model over Model」(MoM)分散式(Decentralized)預訓練研究。簡單來說,MoM是一種「先做小而專,再做融合」策略。不同學科機構可先在本地內部可信環境中,以自家高質量數據,通過預訓練打造70億至130億參數級別的領域模型(Domain-specific model)。這些模型不一定追求最大規模,而是在特定領域具備更深層知識、更專業推理方法和更可靠的學科判斷。
之後,再通過「持續預訓練」(Continual Pre-training),把特定知識灌注至基礎模型當中。進一步而言,透過跨模型融合(Model Fusion)與知識蒸餾(Knowledge Distillation),可以疊加不同基礎模型和領域模型的優勢,形成更強的樞紐型基礎模型。
這種做法有數個重要意義。首先,數據不必外流,有助於兼顧私隱與合規,在本地先發揮數據價值。其次,能力可以疊加;不同模型各有特長,融合後能形成更均衡、更強的整體能力。最後,通過去中心化協作,不同機構可在可負擔成本下,利用分散運算資源,共同推動AI應用於科學研究。
理大方向的關鍵差異
Hermes、Fugu和Fusion主要展示的是推理(inference)階段的多模型協作:系統在回答問題時調用不同模型或agent,多角度產生答案,再進行整合。
理大MoM則更進一步。MoM不是只在現有模型之上做推理時聚合,而是讓不同學科自行發展領域專家模型,吸收本地高質量數據、學科知識、專業推理方法和研究邏輯,再通過持續預訓練、模型融合和知識蒸餾,成為更強樞紐模型的一部分。
MoM進行聚合時,參與融合的並不只是「較便宜的reference models」,而可能是真正具備專業知識結構和學科思維方式的domain-specific models。若醫療模型懂得臨床推理,材料模型懂得分子結構與實驗約束,機器人模型懂得控制、感知和物理世界互動,這些專家模型在融合後,不只是提供答案參考,而是把不同科學領域的推理方法帶入同一個智能體系。
因此,理大的MoM若能成功,潛在效果可能比一般推理時多模型聚合更深遠。MoM不只是提升回答質素,而是改變知識如何被注入模型、學科如何參與AI、大學如何重新進入基礎模型創新的核心流程。
InfiFusion顯示「融合有效」
PAAI正搭建面向大學研究與產業的研發基礎,不止提供算力叢集(Computing Cluster),還包括「持續預訓練+模型融合」流程與工具,讓全球大學不同學科可打造自身領域的基礎模型,並通過融合形成更強的樞紐基礎模型。
理大團隊研發InfiFusion技術,正是實踐MoM融合的例子。團隊以不同來源的中等規模模型進行融合,涵蓋在「推理」(Reasoning)或編程能力上表現突出的模型,包括Mistral、Qwen系列(包含Coder與Instruct)以及Microsoft Phi-4等開源模型,並顯示平均能力有顯著增強。
這一點與Hermes MoA、Sakana Fugu、OpenRouter Fusion和Sakana過去的model merging研究趨勢一致:不同模型可以互補,協作與融合可帶來超越單一模型的效果。不同之處在於,InfiFusion的目標不是簡單組合開源和閉源模型,而是為大學和研究機構建立一套可重複、可擴展、可分散參與的AI研發框架。
重塑Scaling Law
當訓練成本下降,更多團隊便有能力啟動「預訓練+融合」的迭代流程。每個機構都可以擁有自己的模型,並對樞紐型基礎模型作出貢獻。Hermes MoA 2.0顯示,多模型聚合可以用較低成本換取更強能力;Sakana Fugu顯示,多智能體系統可以被包裝成一個簡單可用的模型服務;OpenRouter Fusion顯示,多模型評議可以在必要時提升答案質量;理大PAAI和楊紅霞教授團隊提出的Model over Model,則進一步把這種協作思維推向預訓練、持續預訓練和模型融合層面。
換言之,Hermes、Fugu和Fusion證明,多模型協作正在成為AI應用層方向;PAAI則嘗試把同一套邏輯推向更基礎、更長遠的科學研究與模型建設。AGI可能不是一個孤立巨型模型,而是由不同專家模型共同構成的智能生態。PAAI提出的MoM與InfiFusion,正好站在這個轉折點上。