



新科技速遞
華為全聯接(Huawei Connect)大會進入了第四屆,主題變成了Advance Intelligence,其實也就是AI人工智能的另一解讀。從另一角度,也是華為從通訊領域進入運算領域,推出多種芯片,挑戰美國在AI算力的地位。
華為從通訊事業起家,從IP通訊到電信技術,直到近期5G,華為也切入企業系統和雲運算,屬下海思半導體也有非常有名,發展出手機用的麒麟芯片,去年公佈通用處理芯片鯤鵬(Kunpeng)和人工智慧芯片Ascend(昇騰)。
通用處理芯片是指類似英特爾X86、IBM的Power、ARM之類CPU,華為麒麟也屬於此類,不過只是用在端終,跟高通Snapdragon一樣。鯤鵬則用於伺服系統和桌面;昇騰則是專用NPU芯片,專門用於Ai運算。
AI是一種基於統計模式的運算,跟以往基於 Rule-based運算,非常不一樣。AI是以深度學習訓練模型,處理傳統運算難以解決的難題。AI訓練不同的模型用於推理,算力的消耗有兩方面,首先是訓練(Training),其次是推理(Inference)。
現時AI訓練的芯片均來自美國,主流利用NVIDIA的GPU作AI訓練用途,其他亦有推出不同的神經網絡處理器(NPU),Google的TPU就是俵俵者。
推理方面,則有各FPGA的廠商,則集中在推理運算;廠商包括了Xilinx和英特爾等,NVIDIA也推出Jetson Nano系列;AWS也有專用於推理的Inferentia芯片等。
市場上只有Google和NVIDIA在AI運算,具備全面方案;其中NVIDIA的GPU加上CUDA和cuDNN,更主導了AI訓練和推理。

AI市場霸主NVIDIA
AI改變近代計算本質,CPU不能處理大量平行運算,NVIDIA開發出平行運算架構,利用GPU處理複雜運算,廣泛應用於深度學習,後期推出的CUDA-X AI包含十幾個專用加速庫,機器學習和資料科學工作負載可加速至高達50倍,為典型AI工作流程中每一步提供加速。
華為的升騰亦集中訓練,雖然說Ascend也有針對推理的產品,不過較缺乏完整生態,相信FPGA廠商仍是主導。

全球最快訓練集群
華為副董事長胡厚崑發佈計算戰略,發佈了全球最快AI訓練集群Atlas 900,機器學習和深度學習都是基於統計的計算模式。
隨著晶片進入7nm年代,芯片晶體密度已近盡頭,專門針對特定用途芯片再度興起。
去年,華為公佈了達芬奇計畫,開發Ascend芯片只是其中一部分,還包括了CANN (Compute Architecture for Neural Networks),屬於芯片和上層架構的介面,類似NVIDIA的CUDA,具備計算張量(Tensor)引擎等。
華為又推出AI計算框架 MindSpore計畫開源,也是繼TensorFlow、PyTorch、PaddlePaddle 等計算框架後,再一個AI 開源框架。現時TensorFlow仍是最流行計算框架,PyTorch則緊隨其後。
ModelArts是面向開發人員一站式AI開發平台,可為機器學習與深度學習使雨的資料,提供清理及半自動化標注、分散式訓練、甚至自動化模型生成,模型按需部署;類似AWS的SageMaker。
2萬億美元藍海
預計5年後,AI計算所消耗算力,占算力消耗總量80%以上。胡厚崑預計未來AI使用仍是暴力算法( Brute-force),勢將耗用更多算力。華為走入計算領域,就是針對算力需求的藍海市場。
胡厚崑表示:「這是2萬億美元的計算產業大藍海,通過對架構創新的突破、對全場景處理器的投資、堅持有所為有所不為的商業策略,以及構建開放生態來佈局戰略。」但華為並不止提供芯片,也具備主板、SSD、網絡技術、Altas模組和卡板等的設計能力,加上Full Stack的AI開發方案,也許是全球唯一端對端的AI方案。
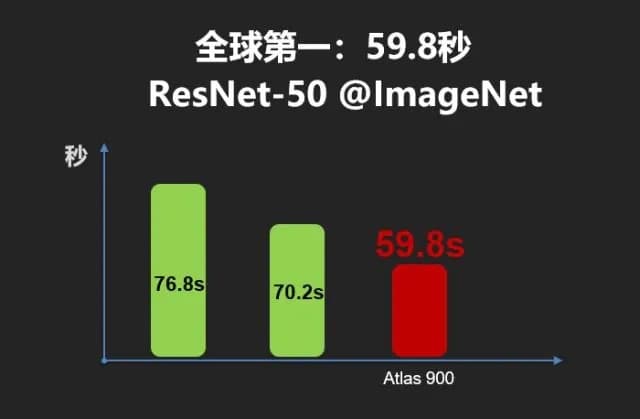
AI訓練集群Atlas 900號稱算力最高,由 1024 顆昇騰處理器組成,衡量AI計算能力的ResNet-50 v1.5模型以ImageNet-1k圖型庫的分類任務,Atlas 900只需59.8秒就完成了訓練,同等精度下比原來的世界紀錄快10秒;舊紀錄分別為70.2及76.8秒。
舊ResNet-50 v1.5訓練紀錄已是超快的極限速度,從舊紀錄一下子減少10秒非常驚人。短期內再超越Atlas 900可能性甚低,也顯示華為整合叢集的網絡技術,非常成熟。
AI驅動算力需求
用於AI訓練的Ascend 910,半精度(FP16),算力高達256 TFLOPS,為業界的2倍,而推理用的Ascend 310的SoC整數精度(Int8)為19 TOPS,支援16通道全高清視訊解碼(H.264/265),功耗只有8W。Ascend 310可以作為邊端視訊解碼,並且備有轉譯工具,即使是利用Café、Tensorflow、PyTorch亦可轉譯供Ascend 310推理。
事實上,去年出現的AI訓練算法,處理圖像的BIGGAN、自然語言的BERT、谷歌DeepMind發表AlphaFold算法,用於份子生物學研究,可自行發現新蛋白質構成,更是震驚生物科技界。DeepLab V3也在語義和圖像分割有甚大改進。上述算法共同特點,均具備極大商業價值,及耗用極大算力。華為以為全球出現AI算力短缺,並非沒有根據。
華為計算架構,從芯片以至軟件架構一應俱全,華為具備芯片設計能力,發展專用芯片,處理AI經常使用的算式,深度學習經常利用的線型算法,標量(scalar)、向量(vector)、矩陣(matrix)、張量 (tensor)。
AI模型訓練消耗了大量算力和成本,Atlas 900可雲端提供了低廉的算力,Ascend 910也推出不同的設計框架和主板設計,供企業內部署AI算力。Ascend 310則部署在邊沿。
AI有助科研發展
如果華為AI算力相較比GPU、TPU、FPGA低得多,可能迫使其他廠商大幅降價,AI可以廣泛應用在其他方面。
Atlas 900算力,可廣泛應用於科學研究與商業創新,比如天文探索、氣象預測、自動駕駛、石油勘探等領域。為了讓各行各業獲取超強算力,華為將Atlas 900部署到雲上,推出華為雲EI集群服務,並以極優惠的價格,面向全球科研機構和大學,即刻開放申請使用。
華為聯合了上海天文台與SKA共同利用Atlas 900分析南半球的星空圖,這張圖上有20萬顆星星,人眼難以看盡浩瀚繁星,以AI分析SKA射電望遠鏡的資料,以往天文學家從20萬顆星星中找出某種特徵星體,需169天的工作量,Atlas 900只用了10秒,可見速度非常驚人。