


我們所生活的世界,是一個立體三維世界。三維,指在平面二維繫中,又加入了一個方向向量構成的空間系。三維坐標的三個軸;分別表示左右、上下和前後空間,這樣就形成了人類的視覺立體感。
那麼,三維世界是如何被我們所看到的呢?
這就不得不談到我們神奇的眼睛。每個人都有兩隻眼睛。其實,一隻眼睛也可看清東西,為什麼還需要兩隻呢?為了說明上述問題,可做一個試驗:
首先,請你的同伴拿一隻鉛筆立在你的視線內。然後,請你閉上左眼,試著去觸碰那只鉛筆。接著,換閉上右眼再試一下。看起來很容易對不對?但你是在試過幾次後才準確碰到的呢?
這個試驗中,左右眼交替時你會發現鉛筆的位置好像變化了,但是當你雙眼同時睜開時,它的位置又好像從來沒有變化。事實上,我們的雙眼確實是分別從不同角度看物體的,然後將兩個投影在大腦中進行合成,從而形成圖像的深度資訊。這個試驗中,閉上一隻眼睛去看,只能形成一個二維圖像,缺乏深度資訊,因此只能依靠經驗去判斷鉛筆的遠近,所以定位,也就沒那麼準確了。
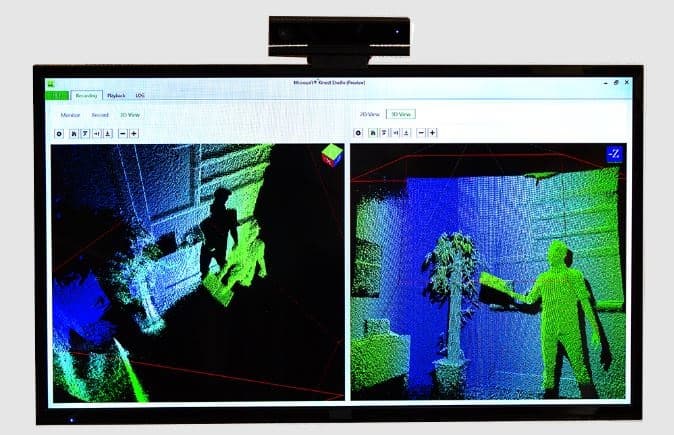
攝像鏡頭是最類似人眼的機械裝置。長久以來,攝像鏡頭拍到的畫面,只屬於二維畫面,直到深度攝像頭的出現。深度攝像鏡頭的相關概念,上世紀80年代,已由IBM提出,首先將其推向民用化,為2005年成立的以色列公司PrimeSense。
一開始,深度攝像鏡頭只用在工業領域,為機械臂、工業機械人提供圖形視覺服務。微軟Kinect成為深度攝像頭在消費領域的開山之作,帶動深度攝像鏡頭技術的民用開發。
2013年,Intel收購RealSense、蘋果收購Kinect技術供應商PrimeSense。2015年Oculus收購Pebbles Interfaces(該公司以VR手勢識別技術見稱),電子巨頭的併購活動,不斷引起大家對深度攝像鏡頭的好奇心。
目前深度攝像頭技術有幾個實現形式:
第一種是以雙攝像鏡頭「視差」,形式就是模擬人眼的機制;原理較為簡單,成本較低。早期深度攝像鏡頭,均以上述方式實現,例如LG的Optimus 3D手機。
第二種是單個攝像頭,通過移動到不同角度捕捉同一場景,然後將幾次拍攝的圖片重組,形成深度的資訊。這種形式較第一種,硬體成本更低,後期在電腦合成三維圖像的過程卻較複雜,成像效果不甚理想。(此形式只可拍攝靜止物體,只可拍照,不能形成視頻。)
第三種是Light Coding技術。以紅外線發射一類鐳射,透過鏡頭前的diffuser(光柵、擴散片),鐳射均勻分佈投射在測量空間中編碼,再經感應器讀取編碼光線,交由晶片運算進行解碼後,產生成一張具有深度圖像。「鐳射散斑」具有很高的隨機性,圖案會隨著距離的不同而變換。也就是說空間中任意兩處的散斑圖案都是不同的。只要在空間中打上這樣的結構光,整個空間就都被做了標記,把一個物體放進這個空間,只要看看物體上面的散斑圖案,就可以知道這個物體在什麼位置了。第一代Kinect就是使用的Primesense的light coding 技術。
第四種是ToF技術。ToF全稱為Time of Flight,是一種利用鐳射探測的主動式深度感應技術。首先讓裝置發出脈衝光,並且在發射處接收目標物的反射光,借由測量時間差算出目標物的距離。ToF相機一般需要使用特定人造光源,一般是紅外線。這種方式成像效果好,但相應地對硬體要求高,成本也高。第二代Kinect就採用了ToF技術,號稱有三倍的精確度。其資料的穩定性相對較好、細節更多;被其他環境光源(紅外線)影響的概率也更低,甚至可以承受一定程度的日光。
目前,深度攝像鏡頭應用消費領域,還處於初期,家用服務機器人行業亦是如此。NXROBO機器人公司抓住了這次先機,使用了深度攝像頭。那麼,當機器人擁有這樣具有3D視覺的“眼睛”時,當它真正能夠“看到”這個真實的世界時,能夠做什麼呢?
(1) 構建三維地圖,即時定位
機器人可構建三維地圖,通過區域劃分識別具體位置,精確導航,自己移動到指定位置;可以自主規劃移動路徑,精準避障。這一功能已逐步應用到家庭安防領域。
(2) 骨骼追蹤,動作捕捉(Skeleton tracking, motion capturing)
根據骨骼追蹤,識別人們肢體動作。通過特殊程式設計,用戶可通過手勢動作,向機器人下達指令。配合智慧傢俱,坐在沙發上,只需打一個響指,電燈暗了,抬一下胳膊,家庭影院開了,然後你就可以吃著爆米花,享受美好的週末了。
(3) 識別人體、物體(Human/object recognition)
通過三維視覺,提高人臉識別和物體識別的準確性,自主尋找指定人和物體。當你在廚房做好飯菜時,機器人到各個房間叫家人吃飯;當你外出時,機器人可幫你看看是否關好門窗等等。當然這樣做的前提是,必須提前訓練機器人識別地點、人和物。
以上這些功能,實現可能或需時日。可以肯定的是,深度攝像鏡頭的出現,機器人朝人工智慧,已再邁近了一步。
作者︰林天麟博士,機械人專家,NXROBO創辦人及CEO。