


[新科技速遞]
近年數學研究圖理論(Graph theory)高速發展,主因是圖理論應用日廣,尤其是互聯網、社交媒體、零售的圖形數據庫(Graph database),都有成功落地商業案例。
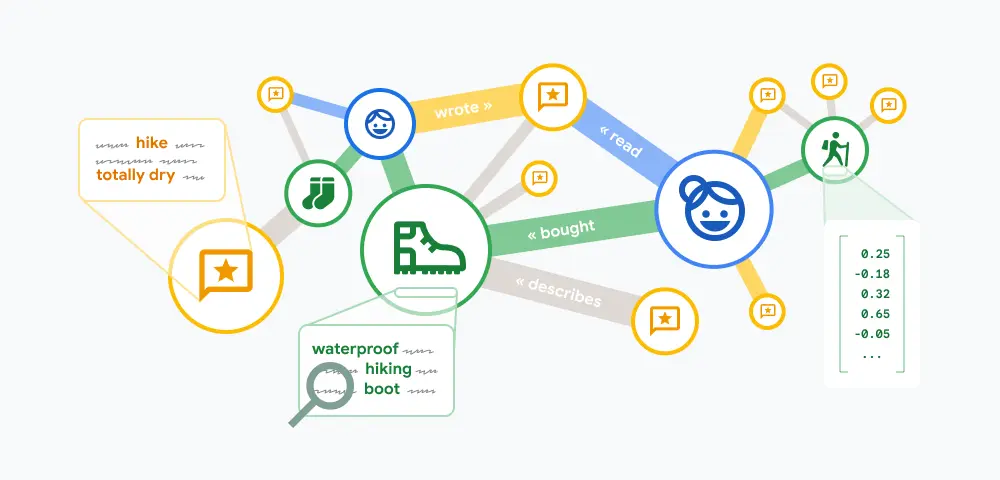
所謂圖形數據庫,乃根據數學上圖理論,以節點(Node)和邊(Edge)為基本元素,通過屬性(Property)描述節點和各個邊特徵。圖形數據庫以實體和關係網絡形式儲存數據進行運算,翻譯經常令人產生誤會,實際上圖形結構指以節點、邊和屬性表示儲存數據進行語意查詢數據庫,與一般圖像關係不大。流行圖形數據庫包括Neo4j、Amazon Neptune和OrientDB等。
Microsoft則更將Graph技術結合到Office 365甚至是Windows作業系統,不少網絡保安均依靠Microsoft Graph提供網絡終端防禦。
最近Google Cloud宣佈在超大型分布數據庫Spanner內,加入了Spanner Graph支援圖形數據庫。Spanner類似是AWS的代管式超大型數據DynamoDB,單點管理可作全球性部署,較早前,Spanner推出了雙區域設定,地理上分割,保留單一全球管理能力,針對不同地區設置,以減低成本和延遲性。

社交網絡早著先鞭
圖形數據庫的價值最早被發現,從可從Facebook、Twitter 和LinkedIn社交媒體數起。社交媒體以圖形數據庫存儲和查詢用戶關係、通過加入朋友圈、瀏覽和交談等行為數據,就可檢索出用戶各種關係、關注和愛好事項,再根據興趣或朋友網絡,推薦內容作投放廣告精凖營銷。
Facebook利用AI從內容檢索出大量數據,效力驚人,甚至影響了英國脫歐公投和美國大選,從推測用戶關注點,甚至影響社交網絡言論,購買決定和各種行為。另一個圖形數據庫的用例,就是推薦個人化產品服務;類似Netflix和Spotify 等根據用戶觀賞數據,推薦歌曲和電影。電子商務Amazon和eBay也以圖形數據庫建立商品推薦。
零售金融業利器
近年,圖形數據庫應用在零售業轉型,用途更加廣泛,包括改進供應鏈現實即日送貨;以縮短補貨時間。圖形數據庫可結合多個數據點關係,例如Neo4j可結合產品、存貨、物流供應商的數據點,自動尋找出最佳送貨途徑和方式。
圖形數據庫一旦偵察特定帳戶交易暴升,再結合金融業不同來源數據,即時可偵察出欺詐活動發生,識別出與欺詐有關的個人或公司。金融機構以圖形數據庫存儲客戶、帳戶和交易資訊,則可檢測可疑行為模式。金融業正利用圖形數據庫偵測詐欺,例如本港警方「防騙視伏器」向市民提供轉賬「高危警示」,以制止電騙發生,向轉數快、網上銀行、電子錢包及銀行櫃枱轉賬發出「高危警示」,並在銀行及電子錢包網頁、手機應用轉賬獲防騙提示。
人工智能成亮點
近期,以圖形數據庫建立的知識圖譜(Knowledge Graph),應用在生成式AI潛力,引起不少關注。
企業部署生成式AI,仍遇到兩個挑戰。首先是答案凖確性不足,其次是出現幻覺( Hallucination)。生成式AI出現後,消費市場引起哄動,企業要求嚴謹,AI落地有不少挑戰。大模型之所以稱為基礎模型,轉用專業用途上,通過要經「微調」(Finetuning),或者通過「檢索增強生成」(RAG)以數據庫加入專業知識。
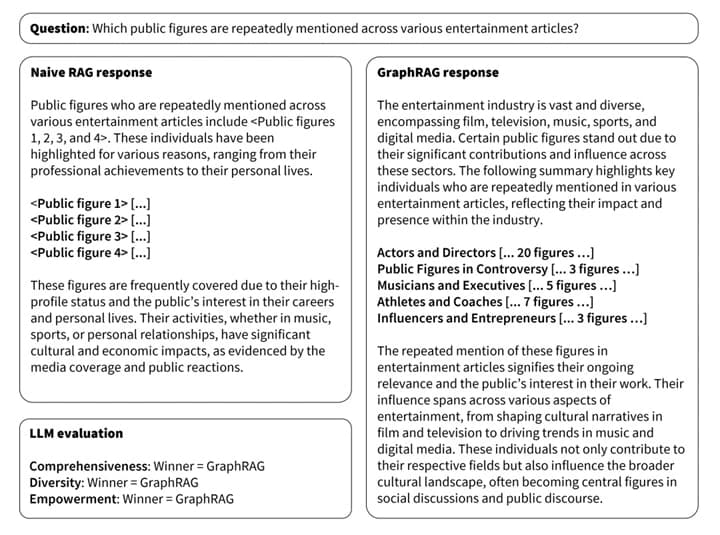
據Databricks的估計,以生成式AI加入專業知識,約有六成的企業採用了RAG,但準繩度強差人意。一般RAG只將文檔變為向量數據庫,再供大模型檢索和生成答案,無法回答全局或高層次問題。
知識圖譜改善AI
7月份,Microsoft開源RAG知識圖譜增強RAG(GraphRAG),幾乎一夜爆紅,迄今獲近一萬五千枚Git Star。大模型通過GraphRAG,可回答複雜問題,答案質素更佳,提高答案可解釋性。GraphRAG利用人類能理解建立知識圖譜,答案易於解釋和審計追蹤,符合企業嚴謹要求。
據Neo4j 技術總監Philip Rathle的解釋,傳統RAG缺乏背景資訊,單從字面關係,推斷出來的答案,既難與已知事物建立關繫,又不提供追源線索,答案的可用性很低。知識圖譜分析複雜問題,可旁徵博引不同關係,從全局視野提高凖確度,尤其生成個人化的答案,表現更為出色。Rathle估計所有RAG都會加入知識圖譜技術。
原來Google也是知識圖譜的先驅,最早追溯至2012年推出第二代搜索引擎,Google加入知識圖譜。Google高級副總裁Amit Singhal揭櫫如何以知識圖譜,提昇檢索引擎質量,近期將知識圖譜研究,套用在生成式AI。
Spanner Graph 可建立類似GraphRAG,以知識圖譜建立大模型,提昇RAG功能,Spanner Graph具擴充性,可容納最大的知識圖譜,內置向量搜尋和 Vertex AI 整合後,簡化生成式 AI 工作流程。