


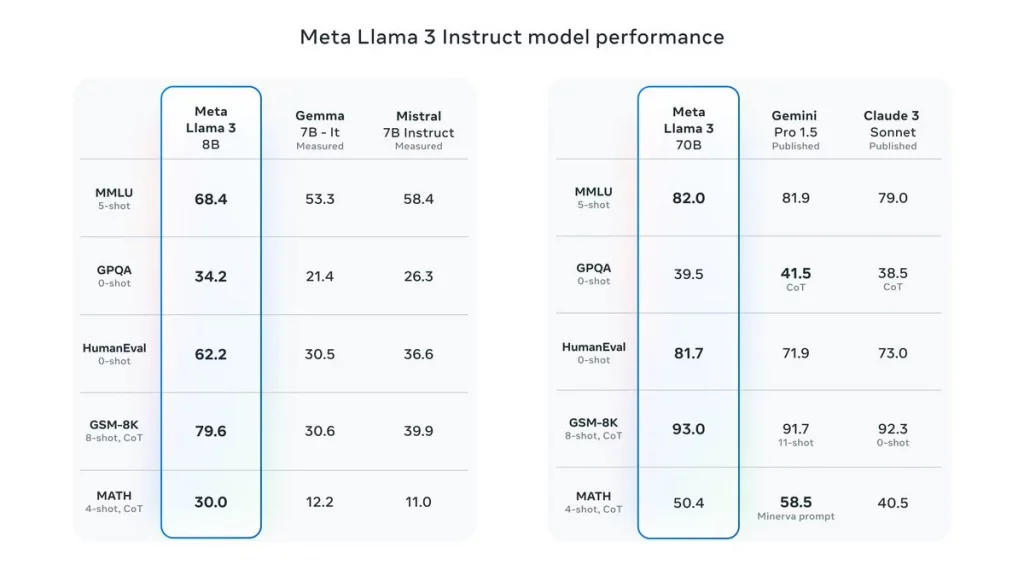
Meta開源Llama 3大模型;包括兩個 80 億(8B)和 700 億(70B)參數版本,已供下載。4000 億參數(400B)版本正在開發,較不少閉源大模型,Llama 3性能有過之無不及,不少評分拋離對手。Meta行政總裁扎克伯格(Mark Zuckerberg)透露,400B在數學(GSM-8K)、編程(Human-Eval)、多任務語言理解(MMLU)基準,超越了GPT4。
8B模型可安裝在消費級個人電腦,例如蘋果Mac機,70B可用於AI的原生應用上。Llama 3也證明了小參數的大模型,性能上完全不遜色,Llama 3在多語言和各方面的能力相當不俗,只要簡單步驟安裝完成。即使針對生產環境,Meta推出微調Llama 3後 Llama Guard 2,能分類大模型輸入提示和回應,可識別不安全內容。
免費開源驅動創新
問題在於,Llama 3是在兩個共24,576塊H100的GPU 集群訓練,成本估計高達1億美元,卻是免費開源,人人唾手可得。Llama 3成為Hugging Face史上,最快躍升第一位大模型。Llama 3未有正式評估,幾乎肯定可與Open AI和Anthropic看齊,Open AI具備了先發優勢,擁有大量企業用戶。開源大模型在全球影響力迅速增長,用戶自由下載並不斷創新。Meta堅持Llama走開源路線,主要是由Meta人工智能科學家楊立昆(Yann LeCun)全力推動。

衍生3萬大模型
全球多個商用大模型,包括Open AI都屬於閉源大模式,無法微調以適應多國語文,估計基於Llama 3微調(Fine-tuning)本土大模型,很快如雨後春筍。去年7月,Llama改變了開源協議,從僅供研究商用,變成「免費可商用」,此後Llama衍生的大模型,一發不可收拾。
Hugging Face 創辦人Clément Delangue在社交媒體X上表示:「迄今Llama 1 和 2衍生的大模型超過了3 萬,估計Llama 3影響更大。 」
楊立昆一直呼籲,大模型要保持開源。大模型要用於某種特定用途,可通過RAG(檢索增強生成)或者微調,甚至提示工程;RAG全靠連接外部數據回應,微調則在預訓練的大模型基礎上,以特定的數據再訓練,模型適應特定任務域。不少從Llama微調大模型,性能竟然更好,不少開源大模型也有同樣現象。
要教曉大模型新的內容,RAG屬常用方法,且有不少公有雲工具支持,用戶數據變成向量,自動供大模型作檢索。開源大模型更容易通過微調,變成特定用途或學會多種語言;Llama有中文和中醫大模型,透過微調訓練再加上提示工程,以少量樣本擴展基礎模型的用途。
楊立昆認爲,開放平台有助於加快大模型開發。Meta後發先至,究竟多少有賴於開源社區?不過全球在文化和語言多樣性,尤其「低資源語言」(Low-resource languages),的確需要AI開源支持。楊立昆認爲美國大模型內容,只是少數人專家去決定,由始至終沒考慮世界其他人的需求。
Llama成國內主流
Llama有多個基於中醫典籍的開源大模型,包括《黃帝內經》HuangDi、《姜子牙》 Ziya和本草大模型,已成為中醫古籍解讀高手,以助普及中醫知識。另一方面, GitHub、Hugging Face、ModelScope、 WiseModel平台,Llama中文社區極為活躍。較早前,北京人工智能研究院向李強總理作出匯報,指國內研究人員過度依賴Llama,可見國內缺乏基礎模型,Llama已成為主流。
楊立昆舉例,前Google研究人員Moustapha Cisse,回到非洲祖國塞內加爾,成立初創Kera Health Platforms,透過Llama提供以塞內加爾語的醫療資訊,當地人均醫生數量極少,類似服務救人無數,Kera剛獲世界銀行的資助。
開源大模型也助多語言國家,打破溝通隔閡,印度有22種官方語言,多家印度初創微調Llama 2;推出Tamil Llama、Kannada Llama、Telugu Llama通曉全部語種。楊立昆說,沒有開源AI平台,不可能有類似的創新。
Llama針對不同的語言、文化、價值體系、不同領域技術能力而微調,甚至根據行業垂直應用再微調訓練,以Meta 內部Metamate大模型為例,可回答Meta內部任何提問。
Meta在社交平台的影響力,商用化早已立於不敗之地。Meta將推出WhatsApp聊天機械人,可助商戶下單,協助電商推廣和生成內容,Meta在社交平台擁大量客戶,以開源營造百花齊放的AI生態,可說利己利人。