


[新科技速遞]
OpenAI橫空出世,多項生成式AI石破天驚,功能已類似技幻小說。原來生成式AI發展,只不過處是開端,開源生態推動生成式AI爆發式增長。
預訓練大語言模型(LLM)理解人類語言,LLM利用網上公開數據預先訓練,學會各種語境獲得知識,通過語言訓練的LLM包含百億以至千億參數,可理解複雜概念之後,執行更多複雜的任務。
類似GPT3.5、BLOOM,Stability AI開發的文生圖模型Stable Diffusion的LLM,亦統稱為「基礎模型」(Foundation Model),原因是可執行跨領域任務;從撰寫博客文章、生成圖像、數學解題、對話聊天、基於文本回答問題,自動開發軟件,甚至具一定程度推理能力。
微調LLM潛力極大
但是,LLM卻非全知全能,例如不可能精通企業內部運作,要通過學習內部文件,才可掌握新技能;例如自動閱讀專業文件,按內容分類回覆。
市場上多種LLM支援API,以「內部文件嵌入」(Document Embedding)形式將內部文件交由LLM分析,通過「指示」(Prompt)程式,抽取內容再生成各種文件和數據。最近,吳恩達deeplearning.ai與OpenAI合作,推出免費網上指示工程課程,講解GPT3.5通過API嵌入內部文件,再生成特定的內容,深入淺出。
https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/
但是,文件嵌入有多個缺點;首先過程繁複,每次開發專門指示;LLM記憶力又受制於查詢容納的Token數量;如果反覆調教才獲結果,API成本可能很高。另一方法則是微調(Fine tuning)LLM,學習專屬領域的知識,回答專業內容和執行任務,成為真正專家助手。
商業潛力無可限量
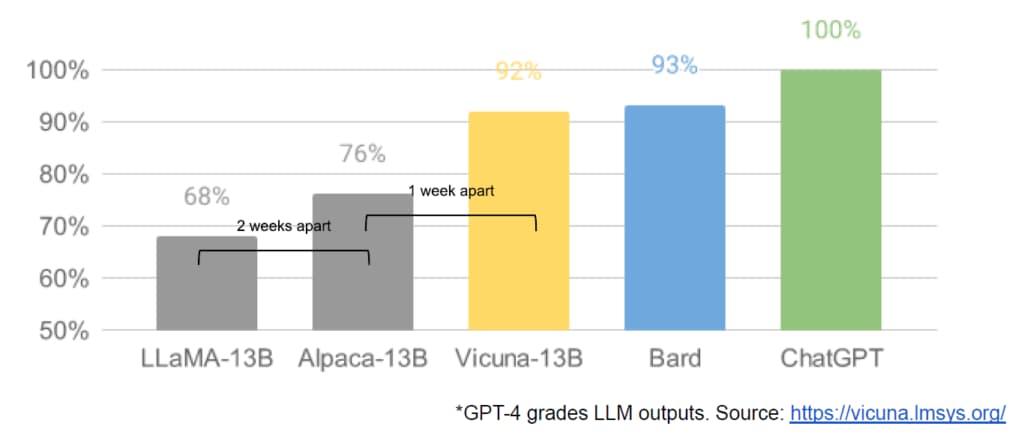
OpenAI的來勢洶洶;3月初FaceBook母公司Meta絕地反擊,開源了預訓練模型LLaMA,其後史丹福大學以LLaMA為基礎,推出類似ChatGPT的Alpaca模型,開源社區Huggingface再以Alpaca微調推出Flan-T5;Hugging face推出了類似ChatGPT服務的Huggingchat交談式AI,加大柏克萊分校又推出Vicuna, Databricks開源了指令調優Dolly 2.0,應用Databricks員工人手撰寫的指令數據集微調,生成式AI演進,速度令人難以置信。開源LLM參數較少,功能毫不遜色,成本更低,微調更快,快速追上ChatGPT。
上述經微調的LLM,勝在毋須從零開始,僅以小量數據和運算資源,通過不同數據微調優化,甚至以「合成數據」(Synthetic Data)生成,迅速降低成本。香港科學園成立數據社群,推廣企業數據協作,亦在本港推廣「合成數據」各種應用,以合成數據甚至保護分享數據的隱私。

微調成本迅速下降
本周,Google舉行I/O用戶大會,生成式AI再度是焦點。較早前,Bard出師不利,Workplace又被微軟Copilot搶去風險,I/O將推出Palm2大語言模型,結合搜尋引擎和Google Lens、生產力平台Workplace等功能,Google Cloud亦會有生成代碼和Code Citation自動整合等功能。
Google和OpenAI財雄勢大,LLM最大應用潛力,卻是模型經微調之後,有望成為個人助手,部署企業內部甚至個人應用,解答疑難和擔任專業任務。
上周,一篇據說從Google外泄文件,以「我們沒護城河,OpenAI亦沒有。」(We Have No Moat, And Neither Does OpenAI)為題,細說Google和OpenAI等面對開源社區挑戰的困局。
據彭博財經新聞的報導,文章作者為Google高級工程師Luke Sernau。他指開源LLM以演進速度驚人,勢不可擋;一周就解決了困擾Google的多項技術難題,開源社區蠶食AI市場,可能是最終勝利者。
多項微調技術出現,大大降低成本,文章提及Low rank adaptation,或簡稱LoRA,以低成本和短時間微調LLM,甚至桌面電腦上就能完成,LoRA模型知識可不斷堆疊,毋須對LLM再完整訓練,減省了成本。
不開源坐以待斃
文章指,即使Google的LLM有短暫優勢,參數較小的開源模型,正以驚人速度縮窄差距。開源LLM速度快、微調和定製能力更強,不用部署在公有雲、更能保護隱私,性能指標更強。作者指,只具130億參數的模型用100美元成本微調,竟可媲美Google以1000萬美元建立5400億參數LLM模型。
文章列舉的各項例子,開源社區的陳述,各項LLM評價,擲地有聲,引來業內鉅大迴響。自從Meta開源了LLaMA,發展一日千里,令人側目。LLaMA在公開時,完全沒任何微調功能,不能靠指令(Instruction)或交談(Conversation)微調;LLM又須與人類意圖「對齊」(Alignment),從用戶反饋直接優化答案,才能遵循人類意圖辦事;OpenAI就是靠獨家RLHF,擁有「對齊」能力。
加入開源主導生態
LLaMA開源後不足三星期內,開源社區發展出微調和對齊工具,支援多模態訓練(Multimodal Training),效果足以媲美ChatGPT和Bard;工具和訓練數據悉數開源,破解速度之快,又具備RLHF對齊。作者指,Google不開源是策略錯誤;呼籲仿照Chrome和Android,集中主導生態系統,與開源社區合作。
文章認為,OpenAI源碼保密的策略,重蹈Google覆轍;面對開源社區競爭, OpenAI優勢遲早會消失;擁大量參數LLM,也不一定具優勢;模型的規模愈大,微調模型參數可行性,越來越低,GPT-3有1750億個參數之多,完整調整模型增加新任務,成本肯定會過高。
LLM模型愈封閉,開源LLM吸引力愈大;企業數據多存放在保安嚴密系統,難以轉移上雲端作訓練;較小LLM具多種微調手法,開源社區又通過無數實驗,快速演進和迭代,潮流浩浩蕩蕩,是否順之則昌,開源與否大概是兩難抉擇。
https://www.semianalysis.com/p/google-we-have-no-moat-and-neither